com.io7m.jpra 0.6.0
com.io7m.jpra 0.6.0 Language Specification
- 1. Notational Conventions
- 2. Concepts
- 3. Statements - Packages
- 4. Statements - Types
- 5. Expressions - Types
- 6. Expressions - Sizes
- 7. Encoding
Notational Conventions
Unicode
The specification makes reference to the
Unicode
character set which, at the time of writing, is at version
8.0. The specification
often references specific Unicode characters, and does so using
the standard notation U+NNNN,
where N represents a hexadecimal
digit. For example, U+03BB
corresponds to the lowercase lambda symbol λ.
EBNF
The specification gives grammar definitions in
ISO/IEC 14977:1996 Extended Backus-Naur
form.
Because EBNF was designed prior to the existence of Unicode, it
is necessary to extend the syntax to be able to refer to Unicode
characters in grammar definitions. This specification makes use of
the standard unicode U+NNNN
syntax in grammar definitions, to refer to specific Unicode characters.
It also makes use of the syntax \p{t}
which should be understood to represent any Unicode character with
the property t. For example,
\p{Lowercase_Letter} describes
the set of characters that are both letters and are lowercase. The
syntax \P{t} should be understood
as the negation of \p{t};
it describes the set of characters without the property
t.
S-Expressions
The jpra language uses
s-expressions as the base for
all syntax. An s-expression
is described by the following EBNF grammar:
symbol_character =
? not (")" | "(" | "[" | "]" | U+0022 | \p{Separator}) ? ;
symbol =
symbol_character , { symbol_character } ;
quoted_character =
? not U+0022 ? ;
quoted_string =
(quoted_character | escape) , { (quoted_character | escape) } ;
escape =
escape_carriage
| escape_newline
| escape_tab
| escape_quote
| escape_unicode4
| escape_unicode8 ;
escape_carriage =
"\r" ;
escape_newline =
"\n" ;
escape_quote =
"\" , U+0022 ;
escape_tab =
"\t" ;
escape_unicode4 =
"\u" ,
hex_digit , hex_digit , hex_digit , hex_digit ;
escape_unicode8 =
"\u" ,
hex_digit , hex_digit , hex_digit , hex_digit ,
hex_digit , hex_digit , hex_digit , hex_digit ;
hex_digit =
"0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" | "0" |
"a" | "A" | "b" | "B" | "c" | "C" | "d" | "D" | "e" | "E" | "f" | "F" ;
expression =
symbol
| quoted_string
| "[" , { expression } , "]"
| "(" , { expression } , ")" ;
As shown, the jpra language
uses an extension of basic s-expressions
that allow for the optional use of either
square brackets or parentheses to increase the readability of large
nested expressions. These should be treated as interchangeable,
but must be correctly balanced as shown by the grammar. For example, the
expression [] is semantically
equivalent to (), but the expression
[) is invalid.
Sets
| Notation | Description |
|---|---|
| e ∈ A | e is an element of the set A |
| e ∉ A | e is not an element of the set A |
| { x₀, x₁, ... xₙ } | A set consisting of values from x₀ to xₙ |
| { e ∈ A | p(e) } | A set consisting of the elements of A for which the proposition p holds |
| |A| | The cardinality of the set A; a measure of the number of elements in A |
| ∅ | The empty set |
| 𝔹 | The booleans |
| ℕ | The natural numbers |
| ℝ | The real numbers |
| ℤ | The integers |
| [a, b] | A closed interval in a set (given separately or implicit from the types of a and b), from a to b, including a and b |
| (a, b] | A closed interval in a set (given separately or implicit from the types of a and b), from a to b, excluding a but including b |
| [a, b) | A closed interval in a set (given separately or implicit from the types of a and b), from a to b, including a but excluding b |
| (a, b) | A closed interval in a set (given separately or implicit from the types of a and b), from a to b, excluding a and b |
| A ⊂ B | A is a subset of, and is not equal to, B |
| A ⊆ B | A is a subset of, or is equal to, B |
Terminology
Most computer programming languages describe
programs that will be executed. The
languages contain elements that describe the static components of
programs - the types - and the dynamic
components of programs - the terms.
The jpra language is a language
for describing fixed-size types
and therefore has no dynamic components. Therefore,
programs written in the
jpra language are more appropriately
described as schemas, and this is the
term that will be used to refer to them throughout this specification.
Concepts
Concepts
Overview
Schemas written in the jpra
language consist of a set of
packages, each containing
a set of zero or more types.
A jpra schema is described by
a series of
statements that
successively describe changes to the schema (such as introducing
a new type, introducing a new package, importing a package into
the current scope, etc).
Statements
A statement in the
jpra language can be
seen as an instruction that performs some action on the current
schema context, yielding a new context that may be changed
in some manner. For example, the
package-end
statement adds a new
package to
the current schema context.
Packages
A package in the
jpra language is the top level
organizational unit for schema objects. A package has a unique
fully-qualified name of the form:
package_name_unqualified =
\p{Lowercase_Letter} , { \p{Lowercase_Letter} | '_' | \p{Digit} } ;
package_name_qualified =
package_name_unqualified , { "." , package_name_unqualified } ;
Types
A type in the
jpra language is a
basic description of the structure of a value. A type has
a unique name within a package, and the format of valid type
names is as follows:
type_name =
\p{Letter_Uppercase} , { \p{Letter} | \p{Digit} | '_' } ;
Statements - Packages
Overview
Overview
This section describes the syntax and semantics of the
jpra language statements that
involve packages.
Scope
Statements inside packages have lexical scope. The evaluation
in package p
of a statement s that binds
a declaration to a name n
makes that declaration accessible by name
n to all successive statements
preceding the end of package p.
Outside of p, a declaration
with name n in
p must referred to
using a qualified reference of the form
p:n. See the
import statement
for details.
package-begin
Semantics
A package-begin statement
that names a package p
sets the current package of the
schema context to p. There can be
at most one current package in
the schema context at any given time.
If the package-begin statement
is evaluated when the schema context already has a
current package, the statement is
rejected with an error.
If the package-begin statement
is evaluated with package name r,
where r is already defined within
the schema context, the statement is rejected with an error.
import
Syntax
package_import = (import q:<package_name_qualified> as r:package_name_unqualified)
Description
A package may import any number
of packages via import statements.
An import statement, given in
the package p, specifies the
fully qualified name of a package q
and an unqualified name r, and
allows definitions given inside p
to refer to definitions in q by
qualifying their names with r.
As an example, consider a package q
that contains a type declaration T.
If package p imports
q using the
unqualified name r, then
definitions inside p may refer
to T using the syntax
r:T.
Semantics
The import statement
makes the declarations of the package
p accessible in the
current package via the name
q, where
q is an unqualified package
name that has not been used in any preceding
import statement.
If an import statement
i
is evaluated with package name p,
where p is not defined within
the schema context, then i is
rejected with an error.
If the unqualified name r
specified in an import
statement i has been
used in a preceding import
statement, then i is
rejected with an error.
Circular Imports
Circular imports are not allowed.
An import statement i
occurring in package p is
considered circular iff:
- i imports p.
- There is a sequence of packages q₀, q₁, ..., qₙ such that p imports q₀, and for all m where 0 <= m < n, qₘ imports q₍ₘ₊₁₎, and qₙ imports p.
package-end
Statements - Types
Overview
This section describes the syntax and semantics of the
jpra language statements that
involve types.
record
- 4.2.1. Syntax
- 4.2.2. Description
- 4.2.3. Scope
- 4.2.4. Size
- 4.2.5. Implementation Constraints
- 4.2.6. Implementation Requirements
Syntax
record_field_padding_declaration = (padding-octets <size_expression>) record_field_value_declaration = (field <field_name> <type_expression>) record_field_declaration = record_field_padding_declaration | record_field_value_declaration record_declaration = (record t:<type_name> f:(<record_field_declaration> ...))
Description
A record statement
creates a new record type. Records can contain fields that can
take one of two forms: A field
form, or a padding-octets form.
The field form binds a name to
a type expression, and the
padding-octets form
inserts explicit padding octets into the record.
Scope
Fields of a record type must be
uniquely named within a single type declaration. The declaration
of a field named f makes that
field accessible by name f to
all successive fields preceding the end of the
record declaration.
Size
The storage size in bits of a declaration
(field n t)
is equal to size in bits of the type
t.
The storage size in bits of a declaration
(padding-octets n)
is n * 8.
The storage size in bits of a given record
t is the sum of the
sizes of all of the fields of t.
Implementation Constraints
There are no constraints placed on implementations
for record types.
packed
- 4.3.1. Syntax
- 4.3.2. Description
- 4.3.3. Scope
- 4.3.4. Size
- 4.3.5. Implementation Constraints
- 4.3.6. Implementation Requirements
Syntax
packed_field_padding_declaration = (padding-bits <size_expression>) packed_field_value_declaration = (field <field_name> <type_expression>) packed_field_declaration = packed_field_padding_declaration | packed_field_value_declaration packed_declaration = (packed t:<type_name> f:(<packed_field_declaration> ...))
Description
A packed statement
creates a new packed type. A packed
type is analogous to a
record type with
the distinction that fields of a packed type may be smaller than
a single octet, may cross octet boundaries, and the sum of the sizes
of all fields typically adds up to
64 bits or less. Additionally,
fields of packed types may only be of type
integer.
Packed types can contain fields that can
take one of two forms: A field
form, or a padding-bits form.
The field form binds a name to
a type expression, and the
padding-bits form
inserts explicit padding bits into the record.
Scope
Fields of a packed type must be
uniquely named within a single type declaration. The declaration
of a field named f makes that
field accessible by name f to
all successive fields preceding the end of the
packed declaration.
Size
The storage size in bits of a declaration
(field n t)
is equal to size in bits of the type
t.
The storage size in bits of a declaration
(padding-bits n)
is n.
The storage size in bits of a given packed type
t is the sum of the
sizes of all of the fields of t.
Implementation Constraints
There are no constraints placed on implementations
for the packed type.
Expressions - Types
- 5.1. Overview
- 5.2. integer
- 5.3. float
- 5.4. boolean-set
- 5.5. vector
- 5.6. matrix
- 5.7. array
- 5.8. string
- 5.9. Reference
Overview
This section describes the syntax and semantics of
jpra language
type expressions.
A type expression is an
expression that, when evaluated,
yields a type. Primarily,
type-checking in the jpra language
is concerned with evaluating type
and size expressions
to yield base types that can then be used to generate code. All
types have a size that is known statically, and the documentation
for each type of expression indicates how this is calculated.
As an example, the type expression
[integer signed 32] evaluates
to a signed integer type with 32
bits of precision. The type expression
[float (size-in-octets T)]
evaluates to a floating-point type with
n bits of precision, where
n is equal to the size in
octets of the type T.
integer
- 5.2.1. Syntax
- 5.2.2. Description
- 5.2.3. Semantics
- 5.2.4. Size
- 5.2.5. Implementation Constraints
- 5.2.6. Implementation Requirements
Syntax
format_expression = "signed" | "unsigned" | "signed-normalized" | "unsigned-normalized" ; integer_expression = (integer s:<format_expression> t:<size_expression>)
Semantics
An expression [integer s t]
describes an integer with t
bits of precision of format s.
If s is
signed, then the type
may hold values in the range
[-pow(2, t), pow(2, t) - 1].
If s is
unsigned, then the type
may hold values in the range
[0, pow(2, 32) - 1].
If s is
signed-normalized,
then the type is considered to hold
signed normalized fixed-point
values. A signed normalized fixed-point
type maps real numbers in the range
[-1, 1] such that
-1 maps to
-(pow(2, b - 1)) + 1, and
1 maps to
pow(2, t - 1) - 1.
If s is
unsigned-normalized,
then the type is considered to hold
unsigned normalized fixed-point
values. A unsigned normalized fixed-point
type maps real numbers in the range
[0, 1] such that
0 maps to
0, and
1 maps to
pow(2, t) - 1.
If s <= 0, the type
is rejected as invalid.
The integer type is considered
to be a scalar type when considered
as an element of a vector or
matrix type.
Implementation Constraints
Implementation Requirements
When specified as the type of a
record field,
implementations are required to support
integers of all formats
of at least the sizes {8, 16, 32, 64}.
float
- 5.3.1. Syntax
- 5.3.2. Description
- 5.3.3. Semantics
- 5.3.4. Size
- 5.3.5. Implementation Constraints
- 5.3.6. Implementation Requirements
Semantics
An expression [float t]
describes an IEEE754 floating point type with
t
bits of precision.
The IEEE754 standard, as of the most recent revision, defines
binary16,
binary32,
binary64,
binary128,
decimal32,
decimal64, and
decimal128 types.
If t == 16, the expression
[float t] denotes the
binary16 type.
If t == 32, the expression
[float t] denotes the
binary32 type.
If t == 64, the expression
[float t] denotes the
binary64 type.
If s <= 0, the type
is rejected as invalid.
The float type is considered
to be a scalar type when considered
as an element of a vector or
matrix type.
Implementation Constraints
boolean-set
- 5.4.1. Syntax
- 5.4.2. Description
- 5.4.3. Semantics
- 5.4.4. Size
- 5.4.5. Implementation Constraints
- 5.4.6. Implementation Requirements
Syntax
boolean_set_expression = (boolean-set s:<size_expression> f:(<field-name> ...))
Description
A boolean-set type expression
describes a packed bit field type
that allows for named boolean flags to be packed into a series
of octets. Individual bits can be queried and set by name in the
resulting generated code, and more space may be allocated than
required for the list of fields to allow for the addition of later
fields without changing the layout of the resulting type.
Semantics
An expression [boolean-set s (f₀ ... fₙ)]
describes an array of named boolean values. The expression
s indicates how many
octets will be used to store the values of the fields.
If the number of fields in f
exceeds s * 8, the type
is rejected as invalid.
If s <= 0, the type
is rejected as invalid.
Implementation Constraints
There are no constraints placed on implementations
for the boolean-set type.
vector
- 5.5.1. Syntax
- 5.5.2. Description
- 5.5.3. Semantics
- 5.5.4. Size
- 5.5.5. Implementation Constraints
- 5.5.6. Implementation Requirements
Syntax
vector_expression = (vector t:<type_expression> s:<size_expression>)
Semantics
An expression [vector t s]
describes a vector of s
elements of type t.
If t is not of a
scalar type, the type expression
is rejected as invalid.
If s <= 0, the type
is rejected as invalid.
Size
The storage size in bits of an expression
[vector t s] is
s * m, where
m is the size in bits
of the type t.
Implementation Constraints
There are no constraints placed on implementations
for the vector type.
matrix
- 5.6.1. Syntax
- 5.6.2. Description
- 5.6.3. Semantics
- 5.6.4. Size
- 5.6.5. Implementation Constraints
- 5.6.6. Implementation Requirements
Syntax
matrix_expression = (matrix t:<type_expression> w:<size_expression> h:<size_expression>)
Semantics
An expression [matrix t w h]
describes a matrix of w
columns and h rows of
elements of type t.
If t is not of a
scalar type, the type expression
is rejected as invalid.
If w <= 0, the type
is rejected as invalid.
If h <= 0, the type
is rejected as invalid.
Size
The storage size in bits of an expression
[matrix t w h] is
w * h * m, where
m is the size in bits
of the type t.
Implementation Constraints
There are no constraints placed on implementations
for the matrix type.
array
- 5.7.1. Syntax
- 5.7.2. Description
- 5.7.3. Semantics
- 5.7.4. Size
- 5.7.5. Implementation Constraints
- 5.7.6. Implementation Requirements
Semantics
An expression [array t s]
describes an array of s
elements of type t.
If s <= 0, the type
is rejected as invalid.
Size
The storage size in bits of an expression
[array t e] is
e * m, where
m is the size in bits
of the type t.
Implementation Constraints
Implementations are permitted to forbid
array types as elements
of array types.
string
- 5.8.1. Syntax
- 5.8.2. Description
- 5.8.3. Semantics
- 5.8.4. Size
- 5.8.5. Implementation Constraints
- 5.8.6. Implementation Requirements
Syntax
string_expression = (string s:<size_expression> e:<quoted_string>)
Semantics
An expression [string s e]
describes a string that may contain at most
s characters. The string
is encoded using encoding e.
If s <= 0, the type
is rejected as invalid.
Implementation Constraints
There are no constraints placed on implementations
for the string type.
Reference
Syntax
type_reference_qualified = package_name_unqualified , ":" , type_name ; type_reference = type_name | type_reference_qualified ;
Expressions - Sizes
Overview
This section describes the syntax and semantics of
jpra language
size expressions.
A size expression is an
expression that, when evaluated,
yields a size. Size expressions
are used to define, for example, the maximum number of elements
in a vector type, or the number of bits of precision in an integer
type.
Encoding
Overview
As stated, the intention of the jpra
language is describe flat data structures that will be encoded into
untyped storage regions. This section defines the rules that are used
to map type declarations to individual octets.
Encoding Rules
Storage Model
The encoding rules described here attempt to describe how an
array of n elements of
a given type T
of size s is mapped
to a flat and untyped storage array of
k octets.
The "first" octet in the array is at octet index
0 and the "last" octet in the
array is at octet index n - 1.
Values are tightly packed; The first octet of the first element
of type T in the array is
at octet index 0, and the
first octet of the second element of type
T is at octet index
s.
Endianness
For record types, for data elements larger than a single octet, the
endianness is unspecified by the
language and is expected to be a configurable property of the
underlying storage. The language encoding rules use relative
terms such as first and
last octets, and these terms are
expected to be interpreted with respect to the underlying storage
endianness.
For packed types, the fields are conceptually packed into a
single integer, and that integer is written to the underlying
storage in big-endian byte order.
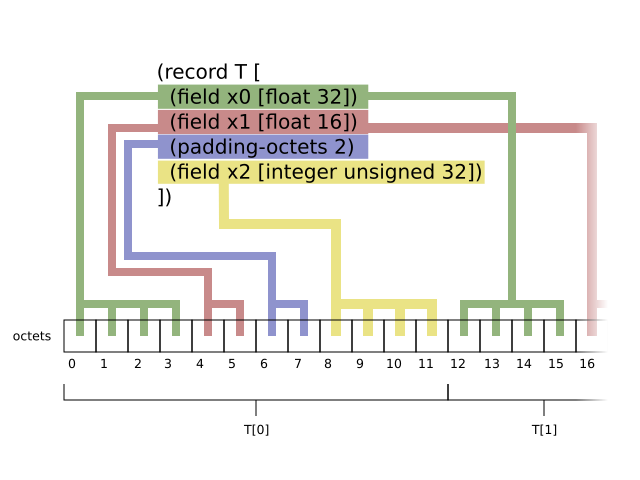
Encoding Records
Fields
The fields of a given record type
T of size
s (octets) are placed
into storage in declaration order. That is, for an element at index
e, the first octet of the first
declared field f0
of T is placed into the
octet at e * s. The next
octet of the field of the field is placed into the octet at
(e * s) + 1. The first
octet of the next field of T
is placed into the octet at
(e * s) + m, where
m is the size in octets of
f0, and so on.
The basic types in the jpra
may impose further rules on encoding, and these are detailed
in the following sections. The rules are specified in terms of
octets within a given field, so if a rule states that some piece
of data is placed at octet 0,
then it is actually referring to the start of the field within
the record type.
boolean-set
The values of the fields of a
[boolean-set s (f₀ ... fₙ)]
expression are assigned sequentially to each bit in the array of
octets, starting at the most significant bit of octet 0. For example,
f₀ will be assigned to
the most significant bit of octet 0,
f₁ will be assigned to the
next most significant bit of octet 0,
f₇ will be assigned to the
least significant bit of octet 0, and
f₈ will be assigned to the
most significant bit of octet 1. In effect, for a given octet,
a true value for
the field n will be encoded
as 1 << (7 - n)
or pow(2, n).
Formally, the field at n
will be assigned to octet n / 8,
bit 7 - (n mod 8), where
0 is the index of the least
significant bit and 7 is the
index of the most significant bit.
vector
For a type t, where
t is of
size s (octets),
the n elements of a
an expression [vector t n],
are stored such that the first octet of the first element is
stored at octet 0, the
second element at
s, and the
(n - 1)th at
(n - 1) * s.
matrix
Matrix data is stored in column-major format
[3]. For an m x m
square matrix, assuming that each element of the matrix uses
n bytes, the first octet of the element at
row r and column c
(assuming 0 <= r < m and
0 <= c < m)
can be found by (c * m * n) + (r * n).
As an example, a 4x4 matrix with 4
octet elements would be stored in memory as shown in the following
diagram:
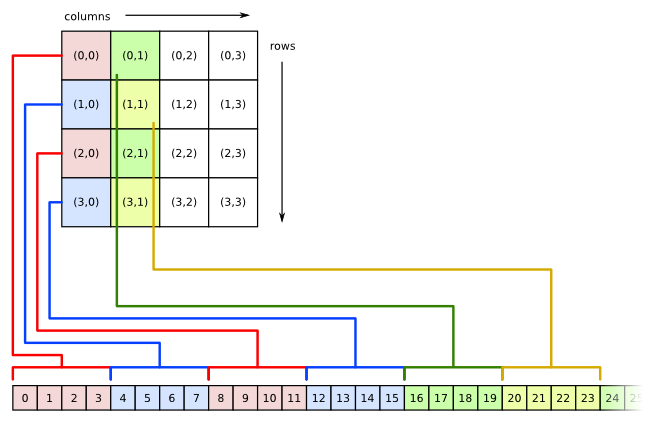
So, the element at row 0,
column 0 would be stored in
octets [0 .. 3]. The
element at row 1, column
0 would be stored in octets
[4 .. 7]. The
element at row 0, column
1 would be stored in octets
[16 .. 19], and so on.
[2]
Most C compilers will insert padding octets to ensure that fields
within a struct have the correct
alignment for the hardware.