Shadow mapping - Basic
Overview
Basic shadow mapping is a technique
that results in simple per-pixel hard-edged shadows. Using the same
view and projection matrices used to apply
projective lights,
a depth-only image of the current
scene is rendered, and those stored depth values
are compared with those in the rendered scene to determine if a given
point is in shadow with respect to the current light.
Algorithm
Prior to actually rendering
a visible set, shadow maps are generated
for all shadow-projecting lights in
the set. A shadow map for basic shadow
mapping for a light k is an image of all of the
shadow casters
associated with k
in the visible set, rendered from the point of
view of k. Each pixel in the image
represents the logarithmic depth
of the closest surface at that pixel. For example:

Darker pixels indicate a lower depth value than light pixels,
which indicate that the surface was closer to the observer than
in the lighter case.
Then, when actually applying lighting during rendering of the
scene, a given eye space
position p is transformed to
light-clip space
and mapped to the range
[(0, 0, 0), (1, 1, 1)], producing
a position pos_light_clip. The
same p is also transformed to
light-eye space, producing a position
pos_light_eye.
The pos_light_clip position is used
directly in order to sample a value d
from the shadow map (as with sampling from a projected texture with projective
lighting). The negated z component of
pos_light_eye is encoded as a logarithmic
depth value using the same depth coefficient
as was used when populating the shadow map, producing a value
k. Then,
k is compared against
d. If the
k
is less than d, then this
means that p is closer to
the light than whatever surface resulted in
d during the population
of the shadow map, and therefore p
is not in shadow with respect to the light.
Issues
Unfortunately, the basic shadow mapping algorithm is subject
to a number of issues related to numerical imprecision, and
the io7m-r1 package
applies a number of user-adjustable workarounds for the problems.
Firstly, the algorithm is prone to a problem known as
shadow acne, which
generally manifests as strange moiré patterns and dots on
surfaces. This is caused by self-shadowing
which is caused by, amongst other things, quantization
in the storage of depth values:
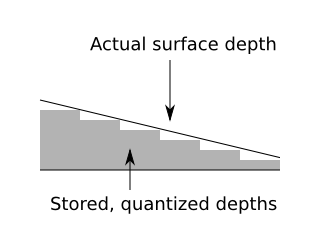
One widely used workaround to prevent self-shadowing
is to bias stored depth values by
a user-configurable amount, effectively increasing the likelihood
that a given point will not be considered to be in shadow. Unfortunately,
adding a bias value that is too large
tends to result in a visual effect where shadows appear to
become "detached" from their casting objects, because the the bias
value is causing the depth test to pass at positions where the shadow
touches the caster.
Another workaround to help prevent self-shadowing
is to only render the back-faces of
geometry into the shadow map. Unfortunately, this can result in very
thin geometry failing to cast shadows.
Finally, it is generally beneficial to increase the precision of
stored values in the shadow map by using a
projection for the light that has
the near and
far planes as close together as the
light will allow. In other words, if the light has a radius of
10 units, then it is beneficial
to use a far plane at 10 units,
in order to allow for the best distribution of depth values in
that range.
The io7m-r1 package
implements both back-face-only rendering,
and a configurable per-shadow bias value.
Unfortunately, neither of these workarounds can ever fully solve the
problems, so the package also provides
variance shadows
which have far fewer artifacts and better visual quality at a slightly
higher computational cost.
Types
Basic mapped shadows are represented by the
KShadowMappedBasic
type, and can be associated with
projective lights.
Rendering of depth-only images is handled by the
KDepthRendererType
type.